
Technical SEO. A phrase of a few words that have been used to cause fear in the hearts of SEOs and non-SEO-focused marketers. It is logical.
With subdomains robots.txt documents, budgets for crawls schema.org marking up, as well as all other aspects typically managed by web developers it can be difficult. Technical SEO is an often overlooked area of web development.
Once you've dived into the basics and know the goals Google as well as other engines trying to achieve (crawling and indexing websites), it is possible developing a plan to optimize your site.
This article will explain technical SEO and why it's essential to rank well, the most important factors to consider and how you can improve your website for future success.
What Is Technical SEO?
Technical SEO is the method of optimizing your site to be crawled and indexed in the phase.
By using technical SEO, you'll be able to aid search engines in accessing the site, crawl, interpret and index your site without difficulty. It's referred to as “technical” since it does not have anything to do with the site's content or even with promotion.
The principal purpose of technical SEO is to enhance the website's infrastructure. To know the actual meaning behind technical SEO, we'll begin with a basic understanding of the term and then dive deep in.
Technical SEO in comparison to. On-Page SEO Vs. Off-Page SEO-h3
Many people divide SEO (search engine optimization) into three categories: on-page SEO, off-page SEO, and technical SEO. Let's go over the meanings of each.
- On-Page SEO
On-page SEO refers to the information that informs Google (and users!) what the page's content is, such as keywords, alt text for images, keyword use, meta descriptions, tags for H1, URL naming in addition to internal linkage.
The most control you have is over SEO on your site since all of the information is the content of your website.
- Off-Page SEO
Off-page SEO informs search engines about how well-known and valuable your site is by granting the votes of confidence that include backlinks or links from other sites to yours. The quantity and quality of backlinks can improve a website's search engine rank.
In all other respects, a page with hundred relevant and useful links on reliable sites can outrank a page with 50 relevant links from reliable websites (or 100 irrelevant links from trustworthy sites).
- Technical SEO
Technical SEO involves diagnosing and solving individual site issues that can't be solved by normal CSS, HTML, or JavaScript alone (using methods such as screen readers, Googlebot and Google Analytics to help diagnose technical problems). On a larger level, it involves thinking about the various ways in which Google interacts with websites at a basic level.
The technical SEO is under your control, too; however, it's more difficult to master as it's not as intuitive.
Why Is Technical SEO Important?
Technical SEO is important because it helps websites rank higher in search engine results. It also helps improve website performance and increase the site's conversion rates.
Technical SEO is a big part of online marketing success because it can help websites generate more traffic and leads, generating more revenue for the business.
Technical SEO is an umbrella term that includes many aspects of optimizing a website's technical components, such as its code, architecture, and performance. Technical SEO includes things like:
- Code analysis
- Crawling
- Link building (both on-page and off-page)
- Mobile optimization
Crawling And Indexing: What Are They, And How Do They Function?
To understand the importance of these optimizations, you must know how search engines index and crawl websites. The more you know about this process, the more knowledge you'll get into optimizing your website.
Crawling
This gigantic metaphor has been taken out of control by websites, crawling, spiders. However, it's true. Search engines release these “crawlers” (software) that make use of websites with existing pages as well as the hyperlinks within those web pages to search for new information.
After they've “crawled” (found the entirety of the links and content) on a site and moved to the next, depending on how huge and well-known your site is, crawlers will frequently return and crawl your website to find out what's changed in addition to what's fresh.
Indexing
After your website is crawled, search engines must allow it to be searchable. The index of a search engine is a set of pages that appear when you type in specific search terms.
The indexing is performed by software known as spiders or crawlers. Crawlers may be able to detect the text automatically from images or optical character recognition (OCR), but the more usual method is to use text tags hidden in the web page's HTML code.
A search engine will periodically refresh its index according to the guidelines you have given it in your code for your website. This includes the frequency of deletions or not, how easily easy to access the contents, and when new content is published.
There may also be major changes to the software that powers the search engine. For instance, Google's mysterious and powerful algorithm changes. We have covered many of these in our blog, check out our SEO News category to find the latest Google changes here: https://underwp.com/category/search-engine-optimization-seo/news/
The search engines can be powerful and powerful. They accomplish numerous things. However, once you are aware of their objectives, you'll be able to build the pieces of your technical SEO strategy.
How to Improve Your Website's Technical SEO
Utilizing keywords, internal hyperlinks and external links, long-tail keywords, and link building are the best methods to show the natural search result. Although these strategies will assist in improving your SEO efforts, there's plenty more to accomplish.
The design of your website is an important aspect of SEO. It is how your site's structure is built, which means it must be designed logically.
If your site has a few pages, it's not going to have any impact; however, in the case of an e-commerce site with a large number of pages, you must ensure that your site is as easy as it can be to navigate.
Let's look at the various aspects of technical SEO techniques.
Site Map
Sitemaps are vital for SEO. The sitemap serves as a map of your website, letting search engines find the sitemap, crawl and index every piece of content.
Sitemaps inform Google what pages on your website are most relevant, the date the last time you updated your site and how often the page's content is updated.
Search Engine Crawling
If you're like most sites, managing crawling is one of the last things you think about. But if you don't take care of it, it can be a major issue for a site's crawl budget.
If you have over 10,000 pages with constantly changing content on your site or more than a million crawlable URLs, you should be aware that managing crawling is an integral part of technical SEO.
For most sites, crawling is not a big issue. When you have a WordPress site, you do not have to worry about crawling issues as they can be managed by good SEO plugins.
On that note, if you looking to build a WordPress website or E-commerce platform, check out our professional WordPress development service here: https://underwp.com/professional-wordpress-website-development-services/
Some CMS's or even the WordPress eCommerce plugins can generate a huge amount of URLs dynamically.
An example of this is faceted navigation on eCommerce stores. Also known as filtered navigation.
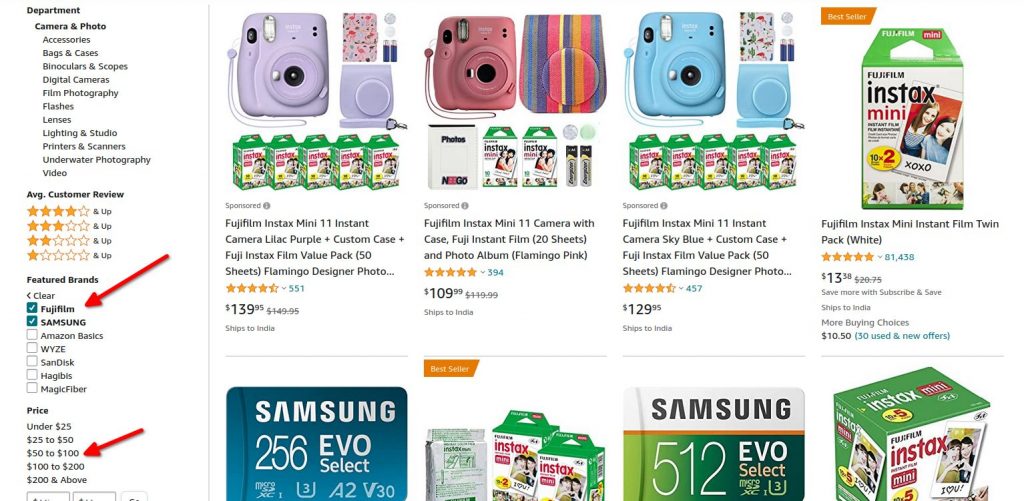
The above example is taken from Amazon. You see the different filters available for the user. Selecting these filters can create an infinite number of URLs.
Let's see how we can manage these URLs.
Robots.txt File
A robots.txt file is a simple text file placed on your web server that gives instructions to search engine robots about which parts of your site they should access and which areas they should not.
It is important to note that a robots.txt file does not tell bots that your site has moved or shut down. Instead, it is a way of telling the bots to keep off certain areas of your website.
This file has to be placed in the root folder of your website hosting space:
https://underwp.com/robots.txtIt is not compulsory thing for a search engine robot to follow all the rules we set in it. But most of the search engine crawlers respect it.
Search engine bots like Googlebot and Bingbots use this robots.txt file to understand your website. If you want to learn about Googlebot and Bingbot IP addresses, check out this post: Googlebot and Bingbot crawler IP Addresses Given By Google and Microsoft
Example 1: Simple robots.txt file
A simple example of a robots.txt file looks like this:
User-agent: *
Disallow: /notme/In the above example, we are telling the crawlers to crawl every part of the website except the notme folder.
Example 2: Images subdirectory in “noteme” folder
User-agent: *
Disallow: /notme/
Allow: /notme/images/In the above example, the “notme” folder is excluded from crawling but its subdirectory images are not. So images sub-folder inside the notme folder will be crawled and indexed by the search engine bots.
Example 3: Disallow URLs containing this text
Use this example if you want do now want to allow the URLs that contain “recent” in the URL.
User-agent: *
Disallow: *recent*The asterisk operator (*) has to be used carefully as this will direct anything that has the specified text in the URLs.
Example 4: Rules for specific bots
We can also create rules specific to one kind of bot.
User-agent: *
Disallow: /notme/
User-agent: googlebot
Allow: /notme/In the above example, we are creating a specific rule for Googlebot saying that it is allowed to crawl and index the “notme” folder while other bots are not.
URL
If you come across a URL with many random numbers and letters that don't provide any information, it's the kind of URL that you'll want to stay clear of because it's not appropriate for any form of SEO.
The idea is to have an URL that is easy to read and provides the user with a clear picture of what the page's about when you wish to link your website.
Links are like re-tweeting or sharing on Facebook: they can expose your content to new people and make it easier for your friends to find you.
Dofollow Links
DoFollow Links are links that pass the juice or credit to the website you are linking to. These links can benefit your site by getting it listed higher on search engine result pages (SERPs) and help with increasing traffic.
Of course, every link is a potential pathway to increased SEO. Using dofollow links in your articles and blog posts can help you receive more authority on the Internet and accomplish your overall marketing goals.
A dofollow link looks like a regular link in HTML
a href="http://underwp.com/digital-marketing-services">Digital Marketing ServicesWhen you link your own website pages, it is called internal links. These links should be dofollow. A general rule is followed by every SEO.
If you are looking to link to an external website, then the decision has to be made if it is to be a dofollow link or a nofollow link. Try to avoid using dofollow links from sources that are not well known and highly involved in the industry.
Nofollow Links
The SEO pros call it a nofollow link but what they mean is the nofollow HTML tag. Tags are the bits of code that tell a browser how to display something. There's an img tag, a cite tag, and so on.
A link tag is the one where we make links on our webpage. And when you put a “nofollow” HTML tag to it it becomes a nofollow link.
a rel="nofollow" href="http://underwp.com/digital-marketing-services">Digital Marketing ServicesThe nofollow tag is one of the most widely misunderstood tags out there. It is at the centre of one of the biggest misconceptions about SEO—the myth that Google doesn't pay attention to nofollow links anymore. That myth has led many SEO professionals to say that SEO doesn't work anymore, as well as many bloggers to complain about “link spam.”

On its own, the nofollow tag does not do anything. The effect of the tag depends on what comes after it. The tag can be used in two different ways: either as a way of marking up links you don't trust or as part of invisible links you want Google to ignore in its search results.
Using the Nofollow tag isn't a surefire way to prevent Google from crawling an internal URL like the robots.txt is, but Google sees it as a sign the page you're linking to isn't important and Google doesn't need to crawl it, as confirmed by John Mueller.
There are situations where the robots.txt file cannot be effectively used to not index parts of your website. Like we discussed above on the eCommerce website.
When the URLs are generated in infinite ways, it becomes difficult to handle in the robots.txt file. This is where Nofollow links can help us in the internal linking for our website too.
Nofollow internal links towards content that is not useful and not to be indexed by search engines are the solution when you cannot control the generation of URLs.
Meta Tags
Metadata means short information about data. Meta tags provide information about the site and directly affect how search engines see it when it comes to websites.
It is essential to have well-structured data since most meta tag elements are designed for the benefit of search engines such as Googlebot and various web crawlers.
In order to ensure proper optimization of metadata, a little keyword research is necessary. Using the correct terms in your articles and technical specifications can aid in increasing your small business's online visibility.
Noindex Tag
Many of the most important SEOs are things that you can't actually see. For example, a noindex tag on a page tells search engines not to index it. If you place this tag, then search engines will ignore the content of this page.
It is a little bit like a password-protected area. But it is not visible to humans and you won't be able to find it in the source code of the page.
The noindex tag is a simple, but powerful way to keep search engines from indexing certain pages.
The noindex tags can be used in two ways on a website:
Meta tags
It does not stop them from accessing the page or using it in the calculation of rankings for other pages on your site.
meta name="robots" content="noindex"This tells all the search robots that this page is not to be indexed.
In a WordPress website, this meta tag function is handled by SEO plugins.
HTTP Header
HTTP header tag is a more advanced way of placing the noindex tag on a page of a website. It is passed as an HTTP header along with other header values. It looks like this:
X-Robots-Tag: noindexMost of the sites use the meta tag option as this implementation would require additional knowledge of how HTTP headers work.
Canonical Tags
Canonical tags are a way of indexing information on the Web. They are called canonical because they are the preferred tags for search engines to use when searching for pages that have identical content on two different URLs, or that have similar content on two different URLs.
If you specify no canonical tags at all, it's like asking search engines to use their own best judgment about which version of your page is the most important.
Canonical Tags don't restrict the content of your page at all; they simply tell search engines which version of your content you prefer people to find when they perform a search.
They can be used by any site that has unique or duplicate pages, so if you run a blog or an e-commerce site, canonical tags can be useful for helping Google find your site more quickly.
Like the Noindex tag, canonical tags can be implemented in two ways. Similar to the implementation of noindex tags.
Meta tag
link rel="canonical" href="https://underwp.com/example-url"Check this wonderful post on our blog where we discussed the canonical URLs and their effects on duplicate URLs. Answered by the SEO team at Google itself. https://underwp.com/case-sensitive-urls-and-its-affect-on-seo/
HTTP Header
The preferred way for both noindex and canonical tags is in the meta tags. But if for some reason you cannot use it in the meta tags of the page, then it can also be implemented in HTTP headers.
Link: https://underwp.com/example-url; rel="canonical"Non-HTML pages use this kind of header like PDF, PPT documents.
Structured Data
Structured data is a unified standard format for presenting data on web pages. Structured data can be used for search engines to better understand the information contained on a webpage and how to display it. It also allows the search engine to provide more useful, integrated search results.
When you have structured data on your website, Google can “understand” the content of your page and therefore display it in a richer way.
For example, Google can show ratings (stars) and reviews directly in search results, or provide summaries of articles and recipes right in search results when you're searching for something like “recipes for chocolate cake with sweet cream” or “movies about World history.”
The use of structured data on websites is increasing. This is because Google and other search engines are using it to provide users with more accurate information and more detailed results.
The structured data on your website can be extremely helpful in getting your website ranked higher in the search results pages.
Schema.org is an open vocabulary that developers can use to markup their pages to describe their content to search engines and other machines (like mobile devices).
It was founded by Google, Microsoft, and Yahoo in June 2011. Since 2011 it has expanded to include representatives from many other companies, including Facebook, Yandex, LinkedIn and eBay.
Learn more about schema.org at https://schema.org/docs/learn-more.html
A few other good reads about the schema implementation from Google docs:
- Introduction to Structured data: Google introduces you to structure data for a website.
- The Search Gallery and Rich Results: A collection of all the rich results seen on Google search results.
- Structure data checking tool: A tool from Google to check the structure data for your website.
Structured Data For SEO Rankings
Having well-structured data for your website doesn't mean it will rank better than others. It is one of the ranking signals.
It will help the Google bots understand your website better. And if they understand it better, then are gonna rank your website or its parts in a better way.
It can also be a tie-breaker in some cases when two pages have similar ranking signals. If a page is well structured, it sure counts as a bonus point for ranking but not the only point that will help you push through competition on search engine results.
Redirects
If a webpage is ever removed from a website or if it changes domain names, both the visitor and the engine will be directed to a new site and an error site if there isn't an existing redirect.
Redirects are crucial for users and search engines since nobody would want to be on a site no longer exists. There are various reasons people would choose to use redirects and various methods for how to do it correctly.
HTTP status codes
HTTP status codes give information about the status of your website or blog post.
HTTP status codes are the messages that web browsers show to users when a web server returns results.
These status codes are part of HTTP (the HyperText Transfer Protocol), which is the set of rules for how computers communicate over the Internet, and they're what a browser uses to display status messages like “Page not found” or “File not found.”
There are many different kinds of status codes, but most webmasters interact with only a few of them.
To learn more about these, these two articles will help you out:
- https://underwp.com/common-seo-terms-for-beginners-in-digital-marketing/
- HTTP 5xx Errors And Their Effects To SEO Of Your Website
XML Sitemaps
XML Sitemaps are the best way to improve your SEO. This is because search engines can index your entire site with one call, rather than having to crawl and index each page separately.
The XML Sitemap allows you to submit a list of all the pages on your site, which is then automatically submitted to all major search engines.
The importance of XML sitemaps can not be overstated. Not only do they help search engines scan your website for keywords and content, but they also allow for quick and efficient indexing. Instead of crawling the entire website, a search engine only has to read the XML files that you provide them with.
The biggest search engines will use this information to crawl and index your website more efficiently and effectively. Most large search engines now support the XML Sitemap format, which means you can submit your sitemap once and it will be picked up by Google, Yahoo, Bing, Ask and others at once.
An example of how a sitemap looks like:
?xml version="1.0" encoding="UTF-8"?
urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
url>
loc>https://www.underwp.com/xml-sitemap//loc>
lastmod>2022-12-14</lastmod
/url>
/urlset>If you look closer at the above example, you will see that it has respective tags to each information on a new line. All the bots and crawlers are easily able to read this information and understand your website.
For WordPress websites, all the good SEO plugins generate XML sitemaps automatically. They also keep it updated with any new information on the website.
HTTPS certification
There are two ways to secure a website, HTTPS or HTTP. HTTPS is more secure because it encrypts data in transit. HTTP is unsecured because it's not encrypted, anyone can access data over the network. HTTP is faster than HTTPS because it doesn't need to do encryption.
You should use HTTPS if you care about your site's security and want to show Google you care about security.
In addition, there are studies showing that Google gives preference to HTTPS sites when users search for terms related to security and privacy. This means that if you're using HTTPS on your site, you'll be given priority in search results over other websites that don't have this security feature.
HTTPS is important for all websites. Especially for the eCommerce websites where financial transactions take place. Crucial user information and transaction information stored with no encryption can lead to the bad reputation of the company too.
Internation SEO
International SEO refers to strategies and techniques used to promote websites on search engines like Google, Yahoo and Bing, which are typically localized and therefore must be optimized to perform well in specific regions or countries.
The main goal of an international SEO campaign is to achieve higher rankings in search engine results pages for a specific country or geographic region. It is a very complex process that involves not just optimizing the content of your website, but also its technical aspects, such as coding and site structure.
It also includes implementing the right keywords and making sure they are correctly translated into the preferred language.
When you do SEO for a site in the United States, it is relatively easy to maintain a big view of the market. You are only working within the market of English speakers in the United States.
As long as you understand that market, and you don't confuse the people in New York with those in Portland or forget about the people who live in rural areas, you won't make too many mistakes.
American search engine optimization is therefore relatively simple. The most important thing is to concentrate on your own area and make sure you understand it well.
But when you do SEO for a site for an international audience, it is not so simple to keep a big view of the market. There are many different markets.
You have to juggle them all in your mind at once, even though they are different cultures using different languages and living in different countries. And then there are various subcultures: hipsters, surfers, gangstas, suburban moms, and more.
We have a complete blog post dedicated to Internation SEO topic and its details here: https://underwp.com/best-guide-for-creating-international-seo-strategies/
When you use SEO plugins on WordPress, they take care of the canonical tags for different languages and regions. An example of a canonical URL for International SEO is like this:
link rel="alternate" hreflang="en” href="https://underwp.com/en/new-page/”
link rel="alternate" hreflang="it” href="https://underwp.com/fr/next-page/”Load Times
The loading speed of a website is the most important aspect of SEO. Any site that has a slow loading speed will lose traffic and customers to its competitors.
Making sure your pages load fast is one of the primary aspects of technical SEO. If users wait too long for the website to load, they'll probably become frustrated and move to the next website that loads quicker.
Technically speaking, there are three factors that determine how quickly a page can be built:
- The markup language of the page (HTML, XHTML, XML, etc.)
- The size of the content of the page (word count, number of images, etc.)
- The load time of any external resources (images, flash files, etc.)
There are many factors that can affect the loading time of external resources.
If you want to make sure that your site is fully optimized for search engine optimization as well as user experience and usability, you should use a professional SEO services company like UnderWP.
CDN (Content Delivery Network)
A content delivery network (CDN) is a large distributed system of proxy servers deployed in multiple data centres. The goal of a CDN is to serve content to end-users with high availability and high performance.
The best way to improve your website loading speed is by using a CDN (Content Delivery Network). A CDN allows you to load your website faster and more securely without any additional coding or programming.
A CDN will store copies of your files in multiple locations around the world, which means that visitors from distant locations will be able to access your site more quickly.
Your visitors will see the benefits of CDN as soon as they hit your homepage.
Content delivery networks are made up of servers, called edge servers or edge nodes, that are deployed at the network edge, which enables them to provide content on behalf of a content provider. These servers often make use of caching techniques, as well as joining their resources to become a larger cache, to provide faster service to users than may be available from the content provider.
Content providers such as media companies, e-commerce vendors and large enterprises often employ their own CDN for Internet-based services, such as for video streaming or software downloads.
When you decide to use a CDN for your website, it is recommended to move all your images, videos and other files from your main host to the CDN server.
If you are thinking about whether or not to use a CDN for your website, ask yourself these questions:
- is my web hosting company using a CDN?
- Are they using one that is close enough to my target audience?
- And lastly, how fast are they loading?
If you answered no to any of these questions then it is better to search for a better hosting company that supports CDN networks.
Most of the hosting companies support the popular CDN network Cloudflare. It is popular and one of the most advanced CDN networks out there that have lots of CDN features for free.
Google's PageSpeed Insights Tool
Google's PageSpeed Insights tool is a clever way to check your website's performance.
It's an online tool from Google that analyzes your site and looks for quick wins in performance optimization. It also checks for any problems that might be causing slow loading times.
The test gives you a score out of 100, where a higher score means you have faster-loading pages. The test measures how well your site loads on mobile networks and checks for potential issues like render-blocking resources, scripts that block the rendering of other scripts and slow loading CSS.
It also displays suggestions for optimization. For example, if it notices that you've got multiple stylesheets on your page, it will suggest that you consolidate them into one. Or if it detects that you're using inline JavaScript, it will recommend that you move them to an external file.
But there's another metric PageSpeed Insights tracks that are more interesting: time to first byte. This measures how long it takes for your server to respond to a request and send some data back to the browser.
You can think of this as the time it takes between someone clicking on a link on your site and seeing something—anything—on their screen. It turns out that fewer people are willing to wait this long than to wait for a page to load altogether.
As soon as people stop seeing something on the screen, they start hitting refresh, which makes it even harder for them to stick around and engage with your content.
Google has stated that they will be “taking into account page load speed as a signal” when ranking search results. They've also confirmed that page speed is a factor in how long it takes to index your content, so making sure your site loads quickly is important both for users and search engines.
Website Structure
A website is like a house. It needs to be built on a solid foundation. Otherwise, it's just not going to work. There are two parts to a website's foundation: its structure and its content. It's important to get both right.
If the structure is bad, it can be extremely difficult or even impossible to fix. If the structure is good, though, you may be able to get away with having less-than-perfect content; but if the content is bad, no amount of clever structure will fix it.
When you have good content and bad site structure, it can result in the drop of Google rankings too. Here are a few tips to help you put the right structure to your website.
Structured URL
Having a proper structure to your URL will result in an easy to understand link for both search engines and website visitors.
https://www.underwp.com/city?id=2156126This kind of URL is not clear what it wants to say about the page.
https://www.underwp.com/uk/things-to-do/Now, this URL is simple to understand for both visitors and the bots. It gives a brief overview of what the content of this link can be.
Having a good structured URL also helps boost your SEO rankings. It is one of the ranking signals for Google.
Thanks to WordPress as it is easy to manage the structure of the website URLs. Just go into the WordPress dashboard and in the Settings part, you will find the subsection called Permalinks.
The permalinks section of the WordPress dashboard gives you various use cases to be used for your website. Or you can put your own structure.
We have a dedicated post here for perfect SEO site URL structure: How To Create SEO Friendly URL Structure In WordPress?
Proper Breadcrumbs
Breadcrumbs are the little markers that show you the trail back to a page from other pages on your site. You see them at the top of every page on the site map.
For SEO purposes, it is also important that your breadcrumbs use the same keywords that you are using on the page.
For example, if you want to rank for the keyword “organic olive oil” your breadcrumbs should say something like “Organic Extra Virgin Olive Oil,” not just “Olive Oil.” By using those keywords in your breadcrumbs, you can help Google index your pages more easily and show up higher in searches related to those keywords.
But don't feel like you have to stuff every single one of your keywords into every single page of your site–that's a sure way to look unnatural and get yourself penalized by Google.
Instead, focus on a few very important pages of your site first (your home page and product pages, for example), and then work out from there.
Pagination
You can get a lot of SEO (search engine optimization) benefit out of structuring your pages to have consistent page numbers.
Websites use pagination to divide parts of the content and arrange them on different pages. This makes it easy to navigate through lots of content. We do this in our blog section here: https://underwp.com/blog
Pagination is also important for eCommerce websites. We recently wrote about its importance in this blog post: Ecommerce SEO Tips And Guide From Google
Javascript Optimization For SEO
Javascript was created as part of a project called “LiveScript”, which was intended to make scripting languages available on the Java platform. However, it was decided to rename it Javascript because the name LiveScript had already been trademarked by another company.
Javascript refers to a client-side scripting language, meaning that it is designed to run on a web browser and produce results that can be seen in real-time by website visitors. It is now used for many other things, including server-side tasks, but for SEO purposes we are concerned with its use on the client-side.
Google bots and other search engine bots are quite advanced now. They can render any kind of javascript and index the resulting content.
But there are still websites and javascript codes that make it difficult for the search engine crawlers to properly render the javascript. This results in a loss of page ranking for websites. Not to say that it also affects the page speed score.
So always make sure your website is rendering the Javascript part correctly for both users and spiders.
Mobile Friendly Website
The mobile friendly website has become increasingly important for SEO. With more people accessing information from their mobile devices, it is important to ensure that your site is responsive and easy to navigate.
Google has made it clear that websites that are not mobile friendly will be marked down in the search results so it's important to ensure that yours is up to date!
There are many benefits to having a responsive website. First of all, it looks better than a non-responsive site: when visiting a mobile site on your phone, you can't help feeling like you are missing out on something by not visiting the full site.
Some sites even take advantage of this by offering an easier-to-access mobile version of their services in addition to their main site.
Often these mobile sites display differently – for example, they may only show contact information or allow you to chat with customer service representatives, as opposed to accessing all of the site's features.
Building a responsive website helps your visitors easily navigate the website. And this will in return also help in the mobile SEO of your website.
Most of the frameworks and themes for websites use mobile-friendly layouts. They also insert meta tags that are useful for mobile devices.
meta name="viewport" content="width=device-width, initial-scale=1.0"This tag is an example where the viewport is set and the content width. Based on the device content width, the webpage will restructure itself and show mobile-friendly content to the visitors.
Hide Page Content From The Search Engines
Crawling happens before a website's page content is indexed in the search engines. This means you cannot index the page if it's not crawled.
This would be true if Google bots and other search engine bots respect the directives o the page in the robots.txt file or meta tags. But this is not the case in reality.
If Google thinks your content needs to be indexed and ranked, then it will still index content blocked from crawling.
This means the meta tags and robots.txt file is helpful to an extent. Now how can you hide your page content?
To get the answer to that, read our blog post here: https://underwp.com/hide-a-website-from-search-engines-like-google/
How To Conduct a Technical SEO Audit
An audit of your technical SEO is a method of evaluating your site to assess how it's performing.
It's also a fantastic method of identifying opportunities for making your website more efficient and better. To make it easier for you, we've put together a checklist of SEO-related tips to assist you in completing the audit.
- Crawl Your Website
This is the first step in SEO. It is also a good practice to follow for any website owner. This will help you find out the weak points of your website and fix them as soon as possible.
Crawling a website is simple and can be done by anyone with a little technical knowledge. There are many tools available online that can help you do this task easily. Semrush has a free crawling option for free trial users upto 1000 pages.
Crawling is a search engine's task. It is the process of finding and following links to ensure that search engines index your website.
You can also use crawling to determine which pages are not indexed by search engines and why. Crawling can be done manually or automatically using crawler software.
It's important to know that crawling can take up a lot of time, depending on the size of your website.
- Check Your Site's Ranking
The most important factor in SEO is the number of pages indexed by Google. The more pages you have, the better your chances are of getting ranked on the first page, which can lead to a higher conversion rate. While other factors play a role in SEO, this is the most important.
The first step in making your website more accessible to the search engines is to check your site's ranking. This includes checking the on-page factors, such as meta descriptions and titles, as well as off-page factors, such as how many links your site has.
- Checking Indexed URLs
Checking indexed URLs is a crucial SEO task. It's necessary to ensure that no pages have gone missing, and also to find any dead URLs or redirects which may have been missed.
Indexed URLs are the foundation of link building. More than anything else, indexed URLs determine how you rank in search engines. Because they are so important, it is important to track the indexation and deindexation of your pages.
The most common way of checking indexed URLs is by using online tools like Google Search Console.
Checking indexed URLs can be done in many ways, including using the “site: domain” operator in Google search or the “site:” operator in Bing search.
- Check Your Redirects and Fix Broken Links
Many websites have broken links, making it difficult for users to find the content they are looking for. This is where redirects come in handy.
The best way to fix broken links is by using a URL redirect checker tool like Semrush to check 301 and 302 redirects. These two types of redirects will automatically fix any broken links on your website.
The first type of 301 redirects, the permanent one, will permanently change the old link to point to your new location and be indexed by search engines.
The second type of 302 redirects, the temporary one, will temporarily change the old link so that it leads to your new location until you decide to replace it with a permanent 301 or 404 page.
A broken link or a redirect can be a huge problem for your website. Check your redirects and fix broken links:
- Redirects are essential for SEO, and they help websites rank higher in search results.
- Broken links can also lead to 404 errors and lower rankings.
- The easiest way to fix a broken link is by using 301 redirects, which tells search engines that the page has been moved permanently.
Conclusion
Technical SEO comprises various options and settings you must make to ensure that search engines index and crawl your site without difficulty.
In most instances, after you've got your technical SEO in order, you will never have to worry about it ever for a while, other than performing periodic SEO audits.
The term technical suggests that you'll have certain technical skills to complete certain tasks (like optimizing page speed and incorporating structured data etc.) However, it's essential to complete it; otherwise, your site won't achieve its full potential.
Having a strong technical foundation for your website will send a strong signal to the search engine crawlers. And if the content is good enough to rank, it will result in better search engine rankings.
In this article, we have covered everything about technical SEO for a website. If there's anything we missed out on or you want to share any important tips, do write in the comments below.
Do not forget to share this post to keep us motivated to write more guides like this that will be helpful to everyone in SEO.


A very well explained guide.
Crawling and indexing are two different things. Your pages can be crawled but it will take time to be indexed.
I believe doing SEO even if not indexed is a good sign to the search engines.
Checking outbound do-follow links can be helpful to gain authority in the rankings of a website. Too much high outbound links from a website to other low authority pages can decrease its authority.