
Now typically as SEOs, that's not what we're trying to do most of the time but there can definitely be a bunch of situations where de-indexing can make a lot of sense.
As SEO pros, we're always constantly wanting to index our content have it rank but in this post, I wanted to talk a little bit about what it is.
How we can prevent indexation and how did the index content especially when it might be content that could be sensitive or could have information that we didn't really want folks to find through google.
So let us start off with why the index matters.
Why Indexing Matters?
As SEOs, we're constantly wanting to rank things and wanting to show up on the index but I wanted us to start off with a refresh of what is the point of it?
Why are we showing up on the index?
What does the index even provide to us?
And when we're talking about the index we're talking about google's search results page that the page that gives you all of the information that a user may be searching for with a specific keyword.
There are three things that it provides for us.
- It increases traffic to our site which is a nice win.
- It also improves our brand awareness, and
- It puts us closer to our business goals.
Now your business could be very different from mine.
An e-commerce site, their business goals could be revenue, could be product sales, product visibility.
A non-profit might be focused on donations or might be focused on increasing its mailing list.
So we got to remember and we got to remind ourselves as we continue to do this indexing work especially when we're messing with the index and having things show up on google?
What is the purpose behind it? why are we doing what we do & so on…
I wanted to show an example of a search term for “Vanagon”.
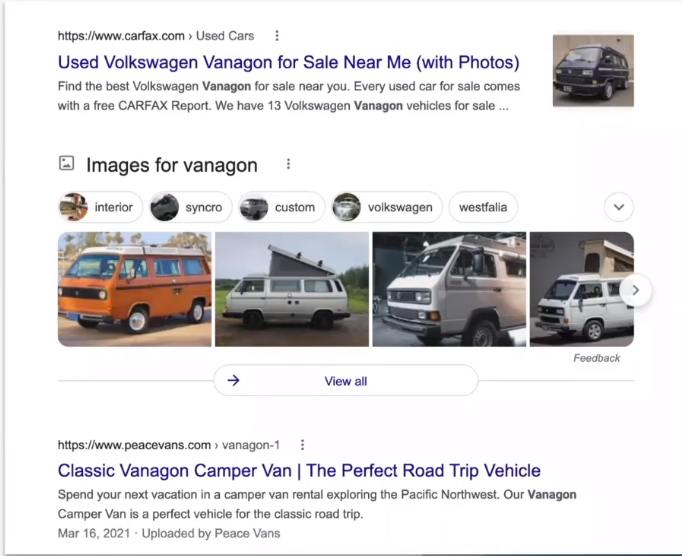
We're seeing a couple of results here the first one we're seeing from carfax is providing users with the availability and visibility to sell and purchase a van.
Then we're seeing a SERP of images and then we're seeing an article by peacevans towards the bottom defining what Vanagon is.
All three different things have different goals and purposes.
Carfax is trying to sell something to you.
Peacevans is trying to let you read something or trying to help you understand something so more informational content.
As users when we're going through google we are trying to find certain things that are going to fulfil our search intent.
My example I've searched for Vanagon, I'm curious to know what that is. I've heard friends talk about it but I don't know what that is right so i want to read the definition of clicking on peacevans.
And at peacevans, I'm now understanding what a Vanagon is. it's vintage, it was manufactured by Volkswagen, the years, etc. It gives me the information that I need.
I've now also built and understood that peacevans is an authoritative figure in regards to Vanagon's, at least in the Seattle area. They're publishing this content that is fulfilling my search intent.
As a user I've understood what Vanagon means, I've also learned about peacevans a business in Seattle that rents out Vanagon but I also know that they know everything about Vanagon's. So if I ever have a question about Vanagon's I know who to go to.
They are also a road trip service so they rent out these vans maybe in the next few days I'll go on a road trip or in a couple of months from now I'll also go on a road trip.
When I'm thinking of my road trip I now understand what business might be around me that provides that service and that is what is completing that goal for peacevans.
I've read their article maybe in a couple of months from now. I decide I'm going to rent that van out and I'm actually going to go on this road trip.
I now have fulfilled one of their other conversions which were to make a sale which was to rent out a van. Their first conversion could have just been viewership. How many times are people actually reading this article?
So now that we have this refresher of what the index means, why the index matters.
Check Indexability
Let's talk about how we find out what from our website is indexed if we were the owners of peacevans.com. What if our site is actually indexed?
If we're trying to find out what is indexed, one of my favourite tools out there that is free and accessible to all website owners is the google search console.
So in the google search console, you have two options on having to find on helping you find the indexability of something.
If I have that peacevans article for Vanagon's and I'm the owner of that site, I want to know whether or not that's the index.
You can use the google search console's URL inspection tool which will tell you information about that page.
So if I throw that Vanagon URL onto the URL inspection tool, the tool will tell me, hey, this page has been indexed.
What date it was most recently crawled. What is the HTML that google is reading?
And another pro of the URL inspection tool is that it's always up to date. It's one of those tools that get refreshed more often than others.
The only con for this or the only downside for the URL inspection tool is you can only look at one URL at a time in its web version.
So if I had hundreds or thousands of pages I couldn't use the URL inspection tool to get those insights. I'd have to use something like the index coverage report we've in the google search console.
The index coverage report will tell you how many pages out of your whole site are indexed.
A recent update on Google search console URL inspection API will help you overcome this limit. Read more about it here: https://underwp.com/google-update-google-launches-new-url-inspection-api-in-search-console/
Whether they are indexed with no issues whether they might have some issues sometimes content can be indexed if it's blocked by robots.txt which I'll talk a little bit about after a few paragraphs.
So that is one of the pros for the index coverage report is it's in a way it gives you a bird's eye view of how many pages are being indexed through your site.
The only con for the index coverage report and I've included a tweet here from google search central is that the index coverage report does not get refreshed as fast as the URL inspection tool.
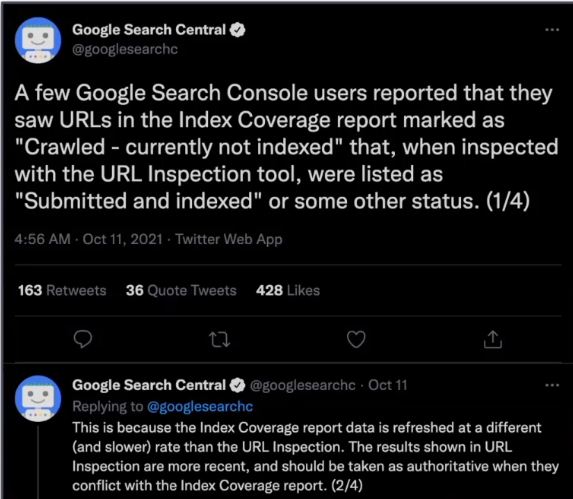
So you might be seeing on the index coverage report that this page is not indexed but if you were to throw that URL onto the URL inspection tool could be telling you something different.
If you haven't already I also highly recommend following google search central on Twitter. They're constantly up uploading some information about bugs or new features that they'll be launching
So give them a follow to turn on your notifications and that way you're always up to date on what is happening with google search console
There are other ways as well that we can look at what's indexed and this is one of the most obvious but also most forgettable.
Google Search Operators
You can act like the consumer or the user you are trying to have to visit your site.
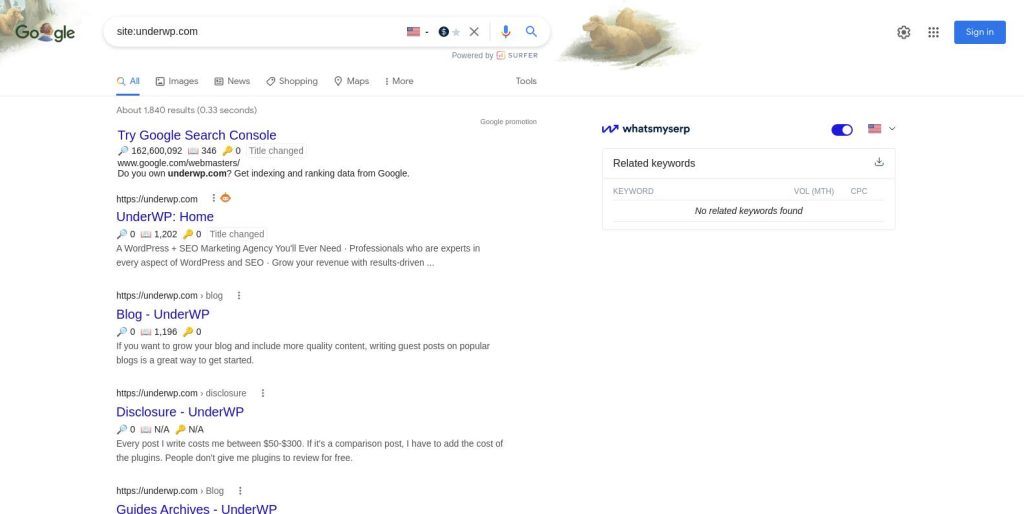
One of the first things you can do is do a site search on google. Use “site:” enter the domain name that you may own.
I've included an example here in the above image of our own website underwp.com
site colon underwp.com and google has now told me how many results fit that or match that. It is now 1,840 results.
So this number we'll take it with a grain of salt. It's not reliable, it can change and it is not going to match the same number 1,840 results with the index coverage report.
We own underwp.com so when we see in the google search console, I don't see that exact same number, so take that with a grain of salt.
it is super helpful if you're doing a competitor analysis and you're trying to understand how many pages your competitor may have indexed. it's a quick way of doing so without having to get access to their google search console.
We have listed the most used search operators on another blog post called https://underwp.com/a-complete-list-of-google-search-operators/
So again I just want to reiterate take this with a grain of salt.
Don't necessarily rely on that site search for your whole domain as something that will tell you exactly how many pages are indexed.
Now if you did do a specific URL search with the site:underwp.com with whatever prefix you're looking at or that URL, if they can be found on google or if you can see it through that google search results page it is indexable.
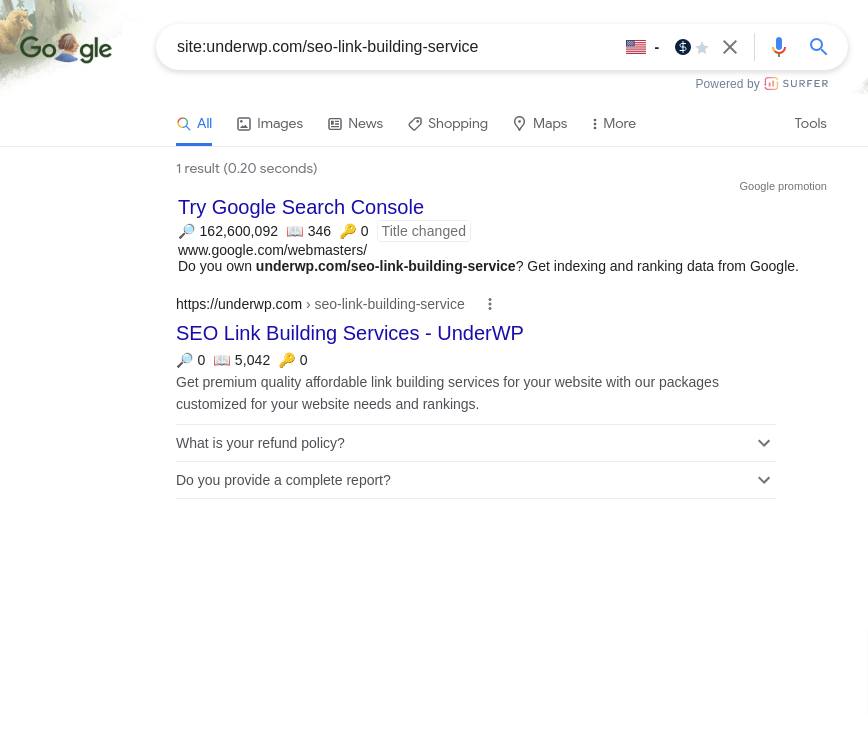
Just remember that if you can access it through google it is an indexable page.
If it's not visible and you're trying to put your URL on there and nothing is showing up then I hate to break it to you that page it's not indexed, so nobody can see it.
Page Templates
Here's another way that when we're dealing with sites that are in hundreds or in the thousands of pages. The way that we may look at different ways to make it easier for us to manage them as SEO pros is to consider page templates.
Consider how you can break your domain or your site into smaller pieces and that's what I'm calling here as page templates.
There are a lot of benefits to it.
They help scale your site if you're going to be creating new content you know exactly what templates to use.
As an SEO worker, you can also look at ways to optimize it by a template.
And we'll talk a little bit more about the different types of templates that exist for different types of businesses.
It will also help you crawl in templates when you know where something is or how something can be found on a specific page type.
You can then in your crawl setup find it or extract that information that you are looking for so you already know what to find
It also helps content teams if your content team is separate from your marketing team or your organic team.
They're constantly writing you content updating information on whether it is on your service landing pages on your blog. They are working with briefs, they have their own templates on how to find the resources that they need to write about.
By providing them templates of the page type that you want them to input this information in, you're also helping them speed up their processes and making sure that it's a lot more reliable towards the end.
It doesn't only just apply to SEOs or to content, it also applies to other channels.
PPC. If your paid teams are creating paid landing pages using templates is going to help them speed up their own processes but also help you look into different ways that you can help optimize those pages.
PPC as one of the teams analytics is also super helpful for the analytics teams but also social media teams or social teams.
Consider page templates as one of the ways that you can really help make larger sites manageable for yourself for your crawls and for others on your team.
So let's talk a little bit now about the different types of templates that exist out there.
E-commerce Page template
When it comes to e-commerce, there are two different types of pages that e-commerce sites use.
They are using product listing pages.
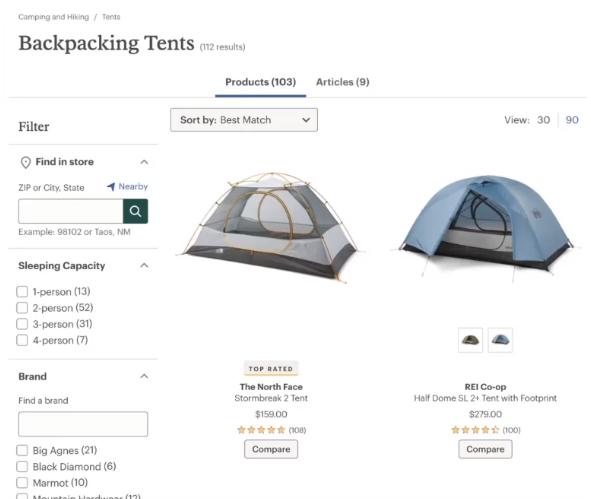
Basically grids of products that are available on a page.
And product description pages.
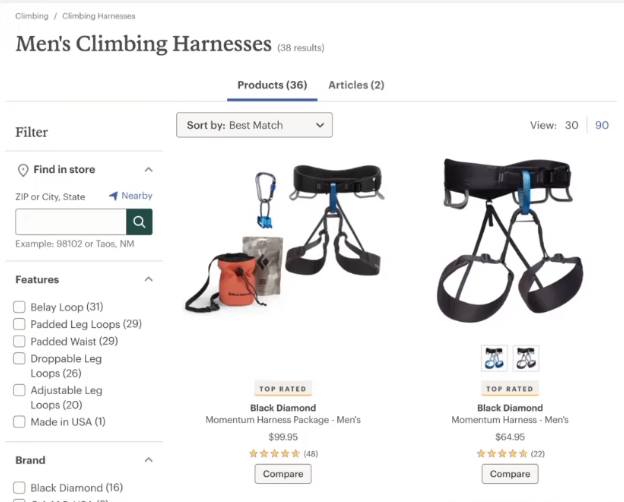
A product description page would be us clicking into one of these tents or one of these harnesses.
The product description pages highlight specifications of a product feature, the reviews if you're interested in reading more about the product, the prices etc.
So that's also a specific type of template and what makes templates easy.
We already talked about the benefits of them for SEO but what makes them a lot easier is how things are in the same place or you can expect things to be in the same place for these e-commerce templates of product listing pages in the above example images.
We are seeing that each one or the title of the pages towards the top
We know that there is going to be a link for articles above the products, we know where the reviews are going to be or where the sort button will be or the page button will be or the filter types.
When you start to know these things, these templates will help you at least.
When you're doing crawling and trying to assess a problem, you can extract certain information because you know where it lives.
So, having yourself be familiar with it is one of also those benefits of having templates on a site.
Note: these are two different types of pages, men's climbing harnesses and backpacking tents. They have completely different search intents. They're customizable and unique but they almost look the same when we're looking at it from a perspective of extracting information.
Content Page Templates
I mentioned earlier that the content teams could use this and they sure can and so can the SEO team

This is lego's news publishing subdomain so this is where lego is constantly launching updates, new products, etc.
Two different types of articles but they both share the same template.
This is super helpful for content writers, especially for content briefs.
They know where that title is going to be placed, they know where the tag is going to be placed, they know where that subtitle will be included and so.
It helps your content writers make sure that whatever they're writing, specially optimized title tags. They know where they go they know what to follow.
Those templates could even be marked by saying, hey, this one section of the site should always be in h2 or it should always be the h1. It helps your content writers and yourself.
Landing Page Templates
Again another example of the types of templates you could use.
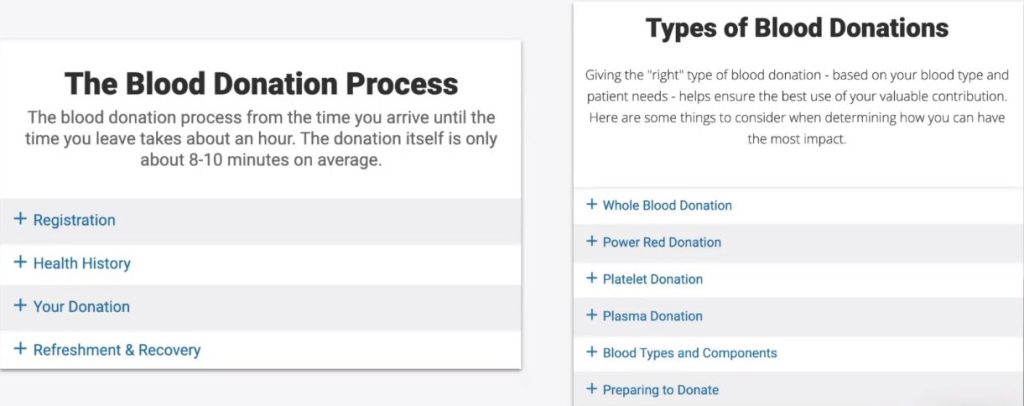
This is for the red cross this is for their donation process.
For folks who are wanting to look at the types of blood donations or the blood donation process.
They follow the same type of template. This is more of a mobile version where they all have a drop-down section.
So their teams are just going in and dropping information or content where they need to based on the template that they're working out of.
Now that we've talked a couple of things.
So far we've talked about the importance of having something indexed. Why does that matter? We've also talked about how you can check on what is indexed? We've also checked on templates.
We're now thinking about how we can work on sites that are in the thousands or hundreds of pages right big sites?
how can I go in and optimize right?
We've got all that covered also in this post.
Examples Of The Type Of Pages To Not To Be Indexed In Search Engines
Let's talk a little bit about the types of pages that we need to know index or that we should consider no indexing.
Now we'll go back to the e-commerce site we talked about.
Ecommerce Filter Pages
On the e-commerce site, we talked about the product listing page, the grid information of different products that are available for a specific thing.
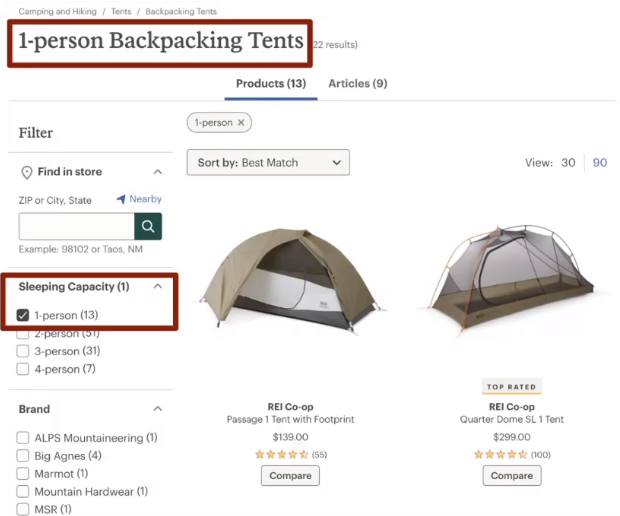
In the above image, we have a product listing page for a one person backpacking tent
You can also see on the second red square that the filter that I have applied here for sleeping capacity is one person.
I wanted to buy a backpacking tent but I only wanted it to fit one person in there so I've applied the filter.
I now see a customized title it says one person backpacking tents. I have all of my options for those tents that fit that filter type.
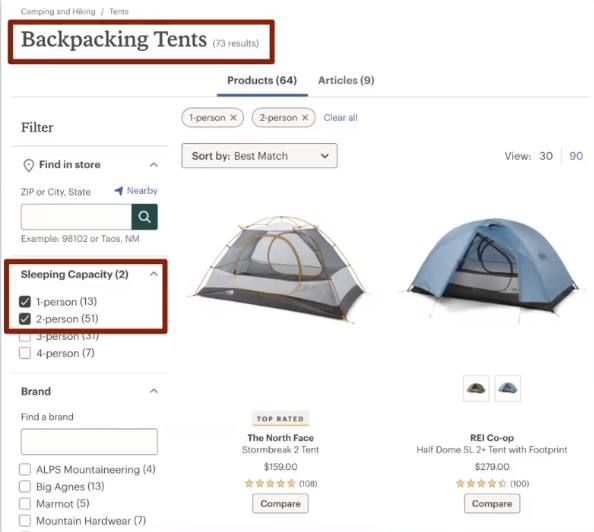
Now, in the above image, I am seeing backpacking tents as a title but if you see closely we have two filters applied, we have 1-person on and an additional 2-person.
So as a user I was curious to see what tents they had that were available for that could fit a one either one person or two person and so it gave me this list of products.
It gets tricky when we're working with e-commerce sites to figure out what is going to be most helpful to the user.
In the first image above of this example, the one-person backpacking tent, it makes sense. There's probably a high search volume for that somebody is looking on google for a one-person backpacking time.
So we want this page to be indexed and we want this page to rank for those terms.
When we're thinking about somebody searching for a one-person and two-person backpacking tent one could assume that that search volume is a lot lower.
And looking at our example here we also can't see a customized title.
It's just backpacking tents in the second image above. We would at least make sure that the second page that we're seeing in the second image above is noindex or that this page cannot be found by Google because it doesn't provide users with any value.
If the users were searching for one person or two person backpacking tent then I would recommend to the above eCommerce site to customize their title tag and make this indexable.
But we have to consider the implications if we are allowing a lot of filter types or filter values to be indexed when the content on our site is not customized or it is a duplicate version of something that is already existing.
So eCommerce sites are definitely or eCommerce pages are one of those things that I would consider or I would suggest folks look into for no indexing
There's a lot of room for error.
You really need to be careful especially when it comes to e-commerce sites.
I showed examples of applying filters and removing them from the index because there could be a lot of filter values you have to consider.
What kind of restrictions do you want to place on your faceted navigation or in your filter selection?
If you allow users or crawlers to find pages that have hundreds maybe tens or five filter values in one URL, those types of pages don't have any value for users.
If they do right, well we'll have to always recommend looking and doing some research on what pages have the most value for them.
That's why we say keep the filters users want.
If there is a high search volume for one person and two person camping tents then let's make that page customizable and valuable for the user.
We also have to consider when working with e-commerce sites is their filter types that are going to be creating duplicate values or duplicate content on our site.
We don't want to confuse Google to decide one page to pick one page over another.
We always want to try to make it easier for Google to know what page to index.
If we have lots of duplicate content or duplicate pages on our site it's going to have to pick and choose which ones to index.
By making sure that we noindex some stuff or some of these duplicate pages we can allow google to focus on the most valuable page.
On that page that we've customized. That we've worked on to make sure that it provides value to the user
Gated Content
Another type of page that you would probably want to know index is your gated content.
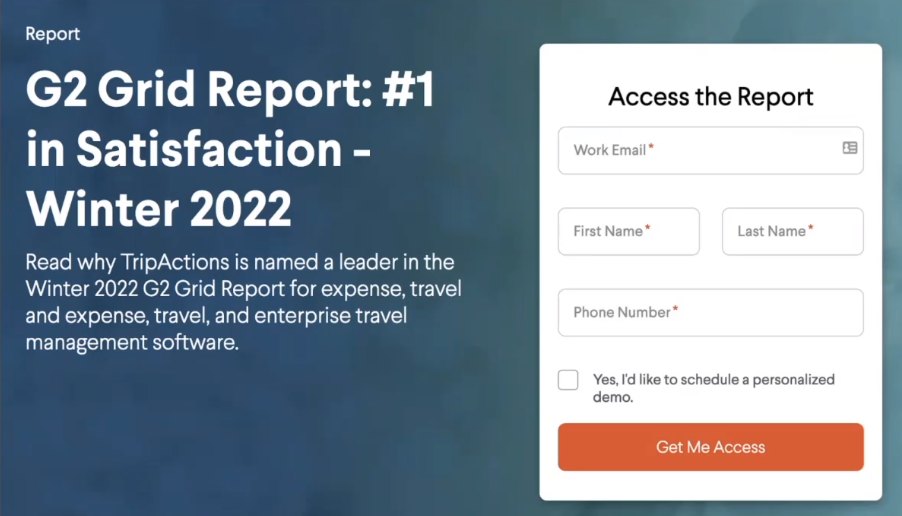
TripActions wrote a grid report.
If I were to search for the G2 grid report of winter 2022 for TripActions, I would find this page where it's asking me for my email my phone number and my name to access the report that is hidden behind this gated content paywall of trip actions.
I am sure TripActions and their team put in a lot of work on making sure that this report is insightful.
It provides a lot of value and therefore people are willing to put their name and their email down because they know that they can rely on or they can count on this report to provide them value.
The most frustrating thing a team could do is to make sure that this report lives on a URL and that URL does not have the no-index tag.
Could you imagine the frustration of a team to know that they have this landing page here collecting emails but somehow somewhere the page that has the actual report on is public or is accessible through google?
If I were to search for the G2 grid report winter 2022, I wouldn't see this page ranking but I would actually see the pdf or that URL. That would be really frustrating.
It would defeat the whole purpose of putting in a lot of work on creating a valuable report when it can be found and that is a common mistake that some companies do.
So always consider your gated content make sure you block it. Make sure you have it with a noindex tag. Make sure it's private.
You want to keep that value there and so checking in on negative content is definitely something I would suggest.
Wishlist
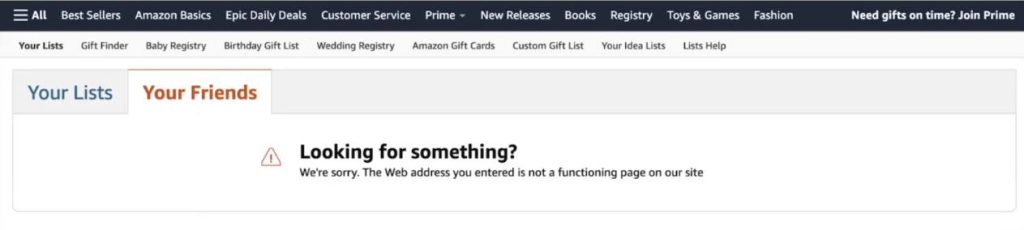
This is a screenshot of Amazon's wishlist.
Any user or customer of amazon can create their own wishlist as they like.
They can add hundreds of items one or two. It's a unique URL. It's unique to the user.
But could you imagine if all of this content was accessible or probable by Googlebot or another search engine?
It would just have hundreds and thousands of pages without any value unnecessary pages.
User-Generated Content
Just similar to wishlist we also have to consider user-generated content on our website.
Maybe I have a website that has a Q&A section where I allow people to type in their questions and other folks in our community answer them.
We have to understand the implications there.
You could be allowing your users to create hundreds of more pages for your site.
On the other hand some of those may be valuable.
Reddit is an example of user-generated content that is valuable.
People want to find and look for those common questions or answers but sometimes we have sections in our site that are related to user-generated content that just isn't important and so we have to consider what the implications are.
Do we want to keep user-generated content accessible to all crawlers so that they can decide whether or not it brings value? Or do we know index a lot of this information and we even prevent google from even finding it? So that they focus their crawl budget on a lot of the important pages on our site.
Lots of questions to ask here.
Consider user-generated content similar to a wishlist as something you would want to noindex.
Cart Pages
Another example similar to user-generated content is cart pages.
Sometimes there are websites or e-commerce sites that do not block cart pages from the index.
They might not have or missing a noindex tag so they are indexable pages and these could be very much unique.
If the URL updates with whatever information it's being added onto a cart it can create chaos of not helping Google understand where to focus on your site.
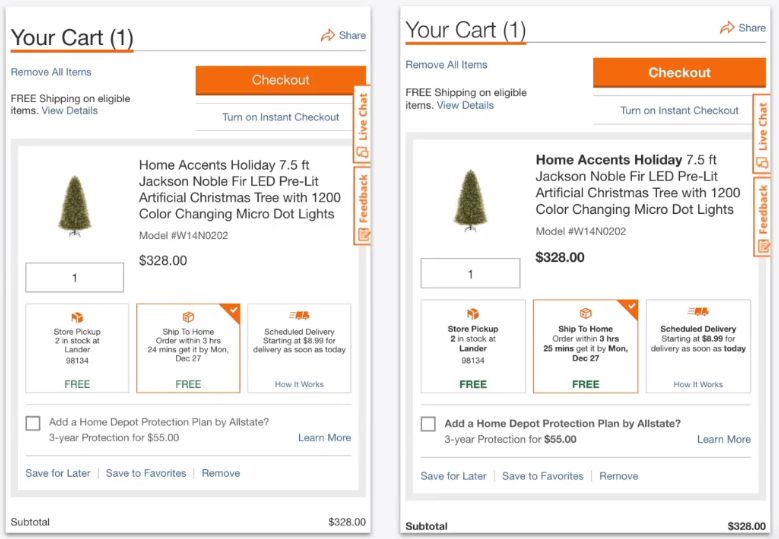
The above image is from home depot a tool eCommerce site. On the left-hand side is the home depot cart URL that I have created.
And I was curious, I wanted to see if by any chance I could also go look at it in my cart or that cart URL was indexed
What I found was that second version or that second screenshot you see on the right-hand side but you can see a little bit of a difference but not too much.
If we were to focus you'll see that the home accents holiday is bolded, the price tag is bolded.
A lot of other terms are bolded and that's because it lives in a completely different domain.
Actually, home depot has a subdomain.
It has a subdomain that is indexed just to look for something related to my cart. You definitely don't want to do that.
I highly suggest making sure that you add no-index tags to your cart pages.
Paid Landing Pages
I've seen teams and companies using a best practice is using your own paid landing page.

Paid landing pages need to be customized.
Sometimes if you're going for a certain audience or a certain niche you want to make sure that page includes certain images or certain keywords or information for that for the users you are targeting or for the ads that you're trying to drive.
Most of the time paid teams do not use pages that are existing on your sites, like your home page or another page they won't be using that.
They tend to create individual pages, at least that's a best practice.
However, sometimes when they do create these unique pages they have to have a unique URL and they forget to block them or they forget to add the no-index tag.
And a lot of the time if they are not blocked they can be found by google.
Whether it was somebody who found the ad on the landing page and decided “oh my gosh, this is a product I really like, I really like this ad I'm now going to write it on my mommy blog and link to it.”
Google has now found its way to that link through backlinks. it's found this duplicate version of a page that already exists on your site
It's now having to start to figure out okay which one do I pick?
The one that exists on the site or the one that is supposed to be a paid landing page but is indexable. always consider and talk to your pay teams about what they are doing for paid landing pages.
Are they creating new URLs or new content? if so that's okay let's just make sure it's blocked for google.
If they are using it and it's not blocked I consider having that conversation now and start figuring out how you can solve that.
And we'll talk in a few minutes about how to actually block it.
Parametrized Pages
The last example of pages to no index is parameterized pages.

The first URL we have coca-cola/original
The second URL is Coca-Cola's original with a parameter that is coming from the coca-cola blog.
And then that third URL is from their social channels.
Those bottom two URLs are unique on their in their own way.
If I were to throw them into google I might be able to find them.
We want to try and focus google's attention on the primary page. the primary page being that top URL.
So there are a couple of ways that we can do this whether it be canonicals or no index tags.
Again it depends on your team, make sure that the two other pages do are not indexable and that the focus remains on the top one.
Prevent Indexation
So far we've talked about templates, we talked about the types of pages now let's talk about how we can prevent indexation.
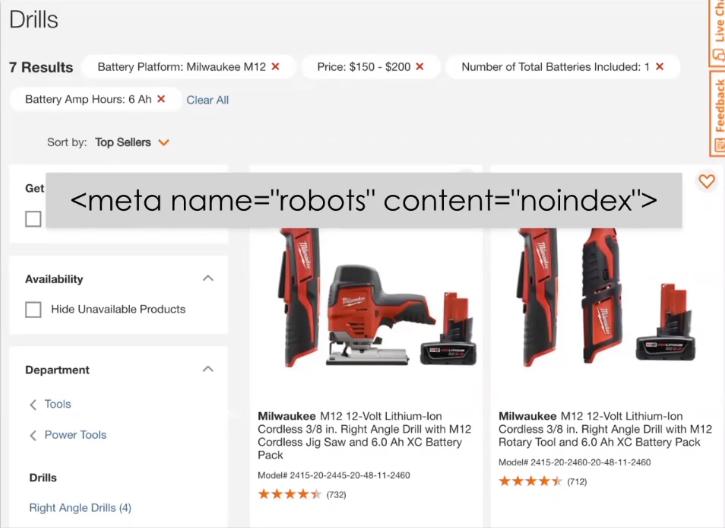
The one the winner of it all how to prevent something from ever showing up on the index is to use the robots.txt.
The noindex tag is a directive.
That means if a search crawler reads the no-index tag or finds it on a page it will not ignore it, it is a mandate. It will make sure that that page is not indexable.
If you ever don't want something to show up on the index make sure that no index tag is included that is a guarantee is that it will not be indexed.
As long as the crawler has visibility to it, one common problem that I've seen clients do is include a robot's no index meta tag with an index meta tag.
It can get confusing. we're trying not to confuse Google as much as we can.
Do not confuse it. let's make it easy for google.
Don't combine a noindex tag and an index tag together.
Just make sure it's a noindex tag by itself.
If you put a noindex tag and an index tag together google will listen to the no-index tag because it's the more restrictive version. It's the one that is going to prevent something.
If you left an index tag on there it does not guarantee that your page will be indexed by google.
So remember the no-index tag is the guaranteed way to make sure that your page does not show up on google's index.
There are a couple of other ways we can do that too
404 or 410 Pages
Page 404 is an error page which means the page is gone.
410 is usually or most commonly used at e-commerce sites which implies no longer available. So this is for products that are gone or no longer exist or will no longer be available.
A 404 or 410 status code or a page isn't exactly telling google to not index it or to not have it show up. But Google is going to decide not to index it or not to show it as users on google because it provides no value.
A page that has a 404 that's an error isn't going to provide any value to any user and so therefore if a page becomes a 404 or 410 in a couple of days you'll probably see it disappear from Google's index or from google search.
I do want to say though that when we're looking at 404 attending something we have to be very careful of the repercussions there. Maybe you had a page that had a lot of backlinks or a lot of good valuable links to it.
By 404'ing it, you're no longer going to have that link equity or that link juice be shared with your other pages.
So you've got to be careful about how you decide to implement this.
Sometimes you might even consider having a sign that says, hey, this product is no longer available on this page, it no longer exists but find yourself this most useful item elsewhere on our page.
So ask yourself and ask other folks on your team what would be the better experience for the user and what would provide the user with the most value.
To learn more about common SEO terms go here: https://underwp.com/common-seo-terms-for-beginners-in-digital-marketing/
Password Protection
Here is our next type of way you can prevent something from being indexed.

Let's imagine that this star wars lego set was not supposed to be visible to users.
It was actually supposed to be private. they were going to launch it in a couple of days.
Again, this is all we're just imagining here, this product is actually is available but just imagine it, okay!
One way that Google can do that you can prevent Google from finding a page is to password protect it.
This is most commonly used for staging environments or sandboxes or where the development is happening in the back end, where users can't see it and you have to insert a username or a password to actually access it.
If this page this star wars product was only visible to the internal teams at lego by inserting a password and a username then google and other search crawlers won't be able to find it and or won't be able to see it because they don't have that username or that password.
If google can't find the page or if search engines can't find that page or see, they are not going to index it.
And that is probably one of the biggest recommendations I ever give any of my clients when we're working through migrations.
And it's one of those recommendations that sounds like it's common sense but it has a lot of high implications that it's worth checking too.
Make your staging environment private and accessible only through password protection.
Sometimes migrations can go really wrong if a staging environment is indexable and available to google.
It's now competing with an actual new site right and so always password protected.
It's one of the best ways you can protect your staging environment and not have duplicate content as well as other confidential or sensitive information.
Now when we're trying to prevent indexation what is not reliable. robots are not taxed.
A lot of SEOs tend to believe that when you put in a robots.txt and it's blocking a page that it means that page will not be indexed by Google and that is a lie!
Google can ignore your robots.txt and it is visible through the google search console.
If your site doesn't report this you're lucky.
You're one of the lucky ones but there are some instances wherein that index coverage report you will see pages indexed by Google and blocked by robots.txt
So it can happen!
Even if something is blocked by robots.txt can be indexed.
Canonicals, Google can also ignore it.
Canonicals is a complex subject but google can decide to ignore one or the other depending on all the other signals.
You have to keep things very precise and uniform throughout your site and sometimes those things can go wrong.
So canonicals are definitely not the way or the approach to guarantee something from not being indexed.
It can help and there are different ways but it is not the most reliable option.
If anything if you want something to no longer show up on the index use the no-index tag.
So we've reached this point now where you're probably asking yourself, ok, you've talked about the different types of pages you know index but I actually have this one page that continues to show up on google no matter what I do.
So for those let's talk a little bit about what it means to de-index something?
How to get it out of the index?
Temporary Removal Tool
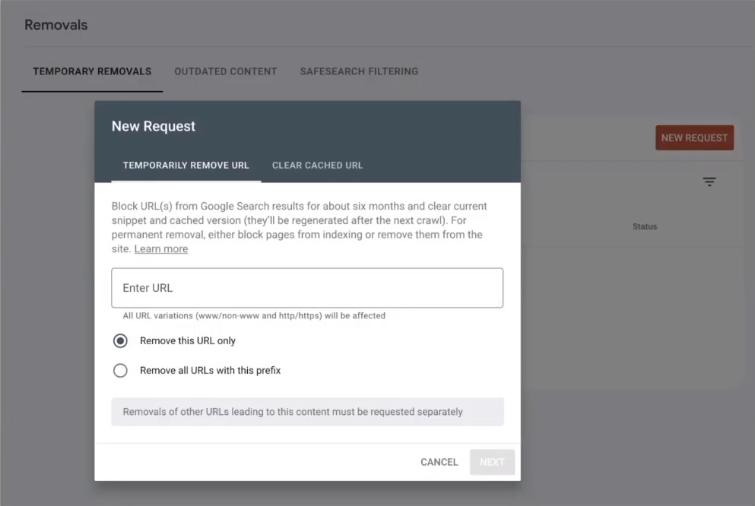
Another thing is available on the Google search console.
The temporary removal tool will help you remove something from google search.
We're only talking about Google here, we're not talking about bing or any of the other search engines but for google.
The temporary removal will make sure that it is no longer visible on Google search.
Let's say I have this one page that had confidential or sensitive information or something that wasn't supposed to launch yet but is now visible on google. we found it through google.
If you add it on here and you enter it to the URL it will remove it from the search. it will not be visible for six months.
However, it is in the name it is a temporary removal that means that this content can still be is still “indexed”, it's just not visible on search.
So there you should be taking some other steps on removing it from the index and those could be adding your noindex tag.
Now if you're trying to scale, the other option is to block a lot of URLs using the same prefix.
Again we're talking about templates here.
If you're using templates of the design of your page and they're very similar to the type of prefix that they use this would be a nice way of doing that, especially, if you're managing a large site.
Okay, so you've got temporary removals and you've now removed this page off of your site, But there's a common instance or a common example that happens in the SEO industry or in the web marketing industry.
“I have a page that has a noindex tag but it is still indexed why is that?”
And to that, I say it's your robots.txt
It probably is your robots.txt
When I talked about no index tags I try to emphasize the importance of making that no-index tag visible to crawlers because that plays an important role.
If you have something blocked by robots.txt, especially google will not go and crawl that page or will not go and see what content exists on that page that even includes a noindex tag.
So if you have a page that has a no-index tag on it but is also blocked by robots.txt then how are search engines or crawlers supposed to even see that no index tags?
They can't. It's invisible to them.
And that is one of the most common mistakes that I've seen in the work that I've done is clients come to me and say, I have all these pages that have a no-index tag but they're still indexed. What is going wrong?
Check your robots.txt
Now you can check your robots.txt using the google search console.
They have a legacy tool and not a lot of sites have access to it these are usually sites that have had google search console for a long time.
I've been very lucky that I've worked with sites that are a lot older and so they have those legacy reports or tools available but if you don't one of my other favourite tools is the realrobotstacks.com
Here's an example of that URL inspection tool.
I've grabbed one of my client's URLs that I know is blocked by robots.txt
I've now thrown it into the URL inspection tool and this is what the report has given me.
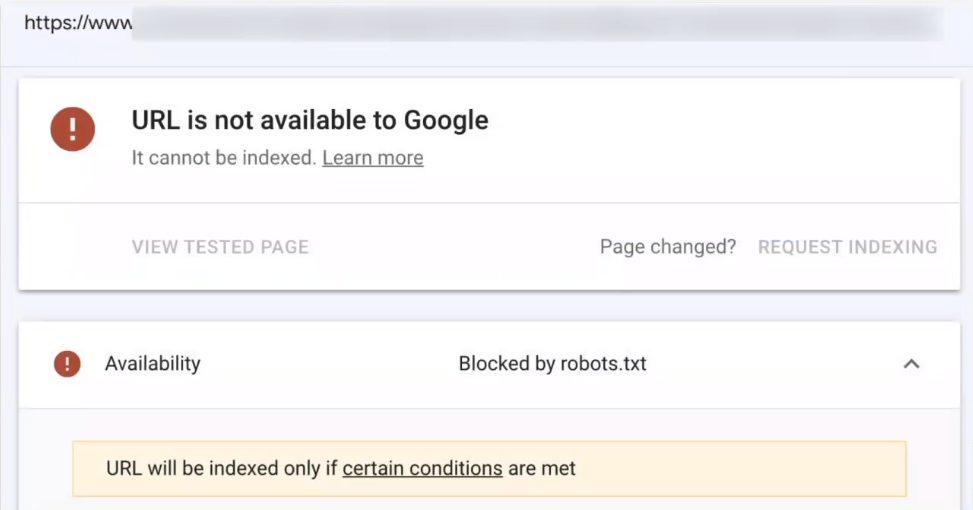
It said your URL is not available to Google. also, it's blocked by robots.txt
Great now I know that this page is blocked.
Let's go test this out. let's go use that legacy report.
The no-index tag and the robots.txt
Search console has that robot.txt tester which is a legacy tool.
It tells you a lot of good information. it will tell you the last time that google or that google bot read your robots.txt
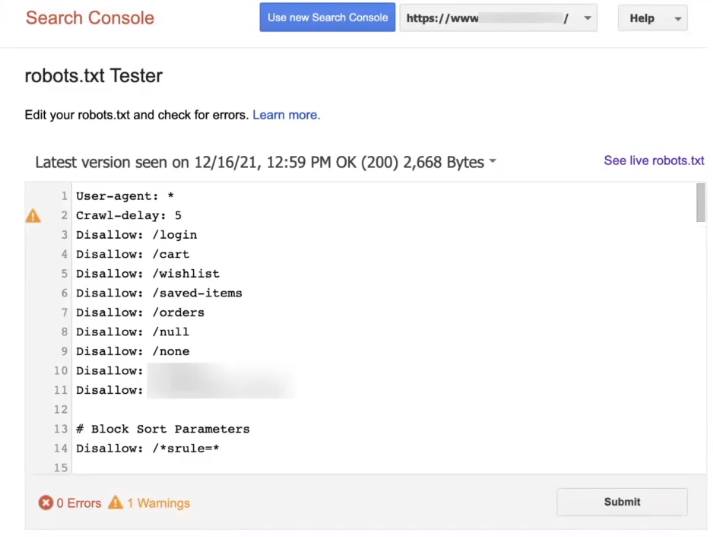
In this example for my client they rate it on December 16th at close to 1 o'clock, that's when they last saw that was on robots.txt
So I know that if I've updated my robots.txt since then a lot of those pages that I've now blocked with an update or have allowed don't necessarily apply or google hasn't even seen that yet.
So we have to wait a little bit.
This legacy tool also allows you to test your updates or it allows you to test certain paths to the disallows and allows.
One recommendation here is if your content is being indexed and it has a no-index tag but it's blocked by robots.txt, Allow it.
Allow that URL to be crawled by google. Keep the no-index tag on your page but allow google and other search engines to actually crawl that page.
So go ahead and put in the allow whether it's on your robots.txt or updating your robots on the text.
Once it's picked up on it and once it's actually read and you can see that through the URL inspection tool go ahead and block that page again on robots.txt or add the additional information.
You just need to build that context for google and give them that one shot of reading it.
Once they've read it they're not going.
Once they read it and you block them again. It will be fine. The page will no longer be indexed.
Check Redirects
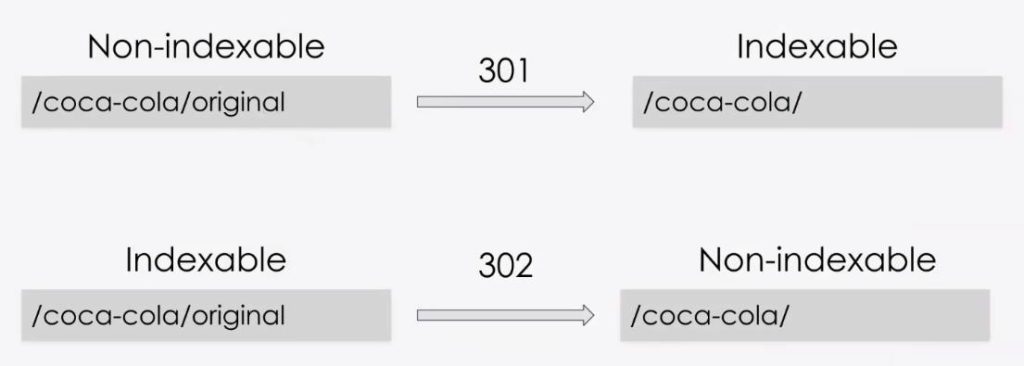
Another thing that we need to check on is redirects. When we are redirecting one page to another.
In the example, at the top, we're seeing coca-cola/original 301s to coca-cola.
That coca-cola original becomes non-indexable because we've done a permanent redirect.
It is now made coca-cola an indexable version.
On the other hand, sometimes people apply the 302 which is a temporary redirect in those instances Google is going to keep that original redirect.
So on the left-hand side now we have coca-cola original 302s to coca-cola but it's temporary.
So what Google is going to do is it's going to keep that coca-cola original URL indexed and it's not going to index that new redirect. especially, if it's a new page.
If it already exists it might keep it on the index.
So check your redirects also.
Checking Canonicals

I touched a little bit about them before in this post.
They are a complex subject so I'll be very brief about it.
We have a blog post as well written by another team member of mine talking a little about canonical tags and their importance: https://underwp.com/case-sensitive-urls-and-its-affect-on-seo/
When you have one page canonicalized to a different page, so page A is canonicals to page B.
Page A becomes non-indexable and page B becomes indexable if page B is what you want to be indexed. great!
If you have page B canonicalizing to itself or has itself referencing canonical then page B becomes indexable.
If you have page B without no canonical and that's why i left it blank. that page b remains indexable.
Because we're telling Google, hey, this page has no canonical to it, it's actually fine, it's indexable.
The only thing here that we've made non-indexable was page A because we've said this one canonical's to page A.
So page A remains to be non-indexable. except when we have a no-index tag.
If page A has a noindex tag and it canonicals to page B, you're running the risk of making page A non-indexable and page B unindexable.
The reason for that is the signals that are found on page A can be transferred over to page B.
I hope that you look into this a little bit further and you analyze your site and make sure your canonicals are set up correctly again.
If you have any questions regarding the canonicals, you can always write a comment below.
Final Words
Use your site's templates to your advantage. get familiar with your site.
Consider the risks and benefits of preventing this indexation.
Some of the benefits are blocking sensitive material from showing up online or confidential information.
The risks are you're losing link equity or valuable backlinks.
Use the tools Google gives you.
Whether that's just google.com or google search console.
And diagnose and assess the following:
- look into your noindex tags
- look into your robots.txt
- your canonicals and
- your redirects
Hope you enjoyed this long post. Show us some love by sharing it and commenting below.


A very long guide. Very long actually but I can understand why it can get longer.
There are so many reasons for one to not index some parts of their website. Explaining with examples in this post can be helpful to a lot of people.
Applying the right kind of technique to deindex the content is the most important decision for any webmaster.